WebValve – The Magic You Need for HTTP Integration
Struggling with HTTP integrations locally? Use WebValve to define HTTP service fakes and toggle between real and fake services in non-production environments.


When I started at Betterment (the company) five years ago, Betterment (the platform) was a monolithic Java application. As good companies tend to do, it began growing—not just in terms of users, but in terms of capabilities. And our platform needed to grow along with it.
At the time, our application had no established patterns or tooling for the kinds of third-party integrations that customers were increasingly expecting from fintech products (e.g., like how Venmo connects to your bank to directly deposit and withdraw money). We were also feeling the classic pain points of a growing team contributing to a single application. To keep the momentum going, we needed to transition towards a service-oriented architecture that would allow the engineers of different business units to run in parallel against their specific business goals, creating even more demand for repeatable solutions to service integration.
This brought up another problem (and the starting point for this blog post): in order to ensure tight feedback loops, we strongly believed that our devs should be able to do their work on a modern, modestly-specced laptop without internet connectivity. That meant no guaranteed connection to a cloud service mesh. And unfortunately, it’s not possible to run a local service mesh on a laptop without it melting.
In short, our devs needed to be able to run individual services in isolation; by default they were set to communicate with one another, meaning an engineer would have to run all of the services locally in order to work on any one service.
To solve this problem, we developed WebValve—a tool that allows us to define and register fake implementations of HTTP services and toggle between real and fake services in non-production environments. I’m going to walk you through how we got there.
Start with the test
Here’s a look at what a test would look like to see if a deposit from a bank was initiated:
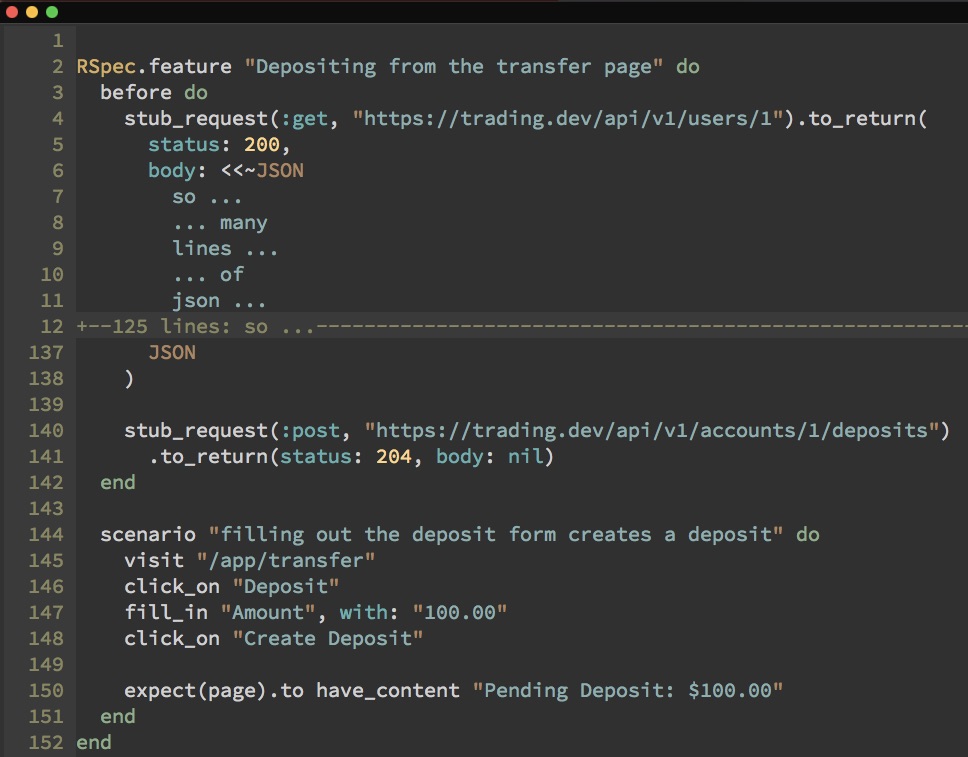
The five lines of code on the bottom is the meat of the test. Easy right? Not quite. Notice the two WebMock stub_requests calls at the top. The second one has the syntax you’d expect to execute the test itself. But take a look at the first one—notice the 100+ lines of (omitted) code. Without getting into the gory details, this essentially requires us, for every test we write, to stub a request for user data—with differences across minor things like ID values, we can’t share these stubs between tests. In short it’s a sloppy feature spec.
So how do we narrow this feature spec down to something like this?
Through the magic of libraries.
First things first—defining our view of the problem space.
The success of projects like these don’t come down to the code itself—it comes down to the ‘design’ of the solution based on its specific needs. In this case, it meant paring the conditions down to making it work using just rails.
Those come to life in four major principles, which guide how we engage with the problem space for our shift to a service-oriented architecture:
- We use HTTP & REST to communicate with collaborator services
- We define the boundaries and limit the testing of integrations with contract tests
- We don't share code across service boundaries
- Engineers must remain nimble and building features must remain enjoyable.
A little bit of color on each, starting with HTTP and REST. For APIs that we build for ourselves (e.g. internal services) we have full control over how we build them, so using HTTP and REST is no issue. We have a strong preference to use a single integration pattern for both internal and external service integrations; this reduces cognitive overhead for devs. When we’re communicating with external services, we have less control, but HTTP is the protocol of the web and REST has been around since 2000—the dawn of modern web applications— so the majority of integrations we build will use them. REST is semantic, evolvable, limber, and very familiar to us as Rails developers —a natural ‘other side of the coin’ for HTTP to make up the lingua franca of the web.
Secondly, we need to define the boundaries in terms of ‘contracts.’ Contracts are a point of exchange between the consumption side (the app) and producer side (the collaborator service). The contract defines the expectations of input and output for the exchange. They’re an alternative to the kind of high-level systems integration tests that would include a critical mass of components that would render the test slow and non-repeatable.
Thirdly, we don't want to have shared code across service boundaries. Shared code between services creates shared ownership, and shared ownership leads to undesirable coupling. We want the API provider to own and version their APIs, and we want the API consumer to own their integration with each version of a collaborator service's API. If we were willing to accept tight coupling between our services, specifically in their API contracts, we'd be well-served by a tool like Pact. With Pact, you create a contract file based on the consumer's expectations of an API and you share it with the provider. The contract files themselves are about the syntax and structure of requests and responses rather than the interpretation. There's a human conversation and negotiation to be had about these contracts, and you can fool yourself into thinking you don't need to have that conversation if you've got a file that guarantees that you and your collaborator service are speaking the same language; you may be speaking the same words, but you might not infer the same meaning. Pact's docs encourage these human conversations, but as a tool it doesn't require them. By avoiding shared code between services, we force ourselves to have a conversation about every API we build with the consumers of those APIs.
Finally, these tests’ effectiveness is directly related to how we can apply them to reality, so we need to be simple—we want to be able to test and build features without connections to other features. We want them to be able to work without an internet connection, and if we do want to integrate with a real service in local development, we should be able to do that—meaning we should be able to test and integrate locally at will, without having to rely on cumbersome, extra-connected services (think Docker, Kubernetes; anything that pairs cloud features with the local environment.) Straightforward tests are easy to write, read, and maintain. That keeps us moving fast and not breaking things.
So, to recap, there are four principles that will drive our solution:
- Service interactions happen over HTTP & REST
- Contract tests ensure that service interactions behave as expected
- Providing an API contract requires no shared code
- Building features remains fast and fun
Okay, okay, but how?
So we’ve established that we don’t want to hit external services in tests, which we can do through WebMock or similar libraries. The challenge becomes: how do we replicate the integration environment without the integration environment? Through fakes.
We’ll fake the integration by using Sinatra to build a rack app that quacks like the real thing. In the rack app, we define the routes we care about for the things we normally would have stubbed in the tests. From here, we do the things we couldn’t do before—pull real parameters out of the requests and feed them back into the fake response to make it more realistic. Additionally, we can use things like ActiveRecord to make these fake responses even more realistic based on the data stored in our actual database. So what does the fake look like?
It's a class with a route defined for each URL we care about faking. We can use WebMock to wire the fake to requests that match a certain pattern. If we receive a request for a URL we didn't define, it will 404. Simple.
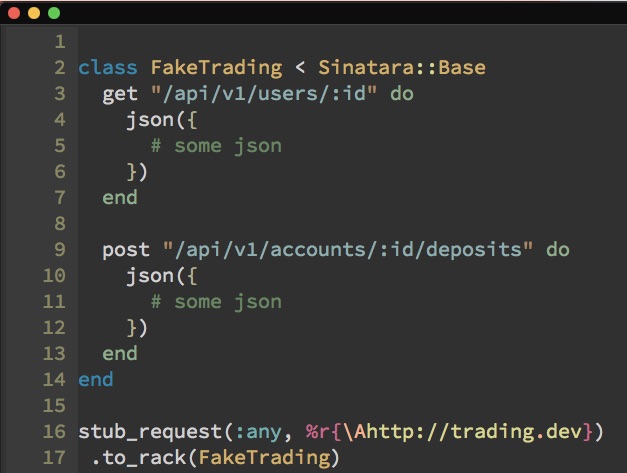
However, this doesn’t allow us to solve all the things we were working for. What’s missing?
First, an idiomatic setup stance. We want to be able to define fakes in a single place, so when we add a new one, we can easily find it and change it. In the same vein, we want to be able to answer similar questions about registering fakes in one spot. Finally, convention over configuration—if we can load, register, and wire-up a fake based on its name, for example, that would be handy.
Secondly, it’s missing environment-specific behavior, which in this case, translates into the ability to toggle the library on and off and separately toggle the connection to specific collaborator services on and off. We need to be able to have the library active when running tests or doing local development, but do not want to have it running in a production environment—if it remains active in a real environment, it might affect real customer accounts, which we cannot afford. But, there will also be times when we're running in a local development environment and we want to communicate with a real collaborator service to do some true integration testing.
Thirdly, we want to be able to autoload our fakes. If they’re in our codebase, we should be able to iterate on the fakes without having to restart our server; the behavior isn’t always right the first time, and restarting is tedious and it's not the Rails Way.
Finally, to bolt this on to an IRL application, we need the ability to define fakes incrementally and migrate them into existing integrations that we have, one by one.
Okay brass tacks.
No existing library allows us to integrate this way and map HTTP requests to in-process fakes for integration and development. Hence, WebValve.
TL;DR—WebValve is an open-source gem that uses Sinatra and WebMock to provide fake HTTP service behavior. The special sauce is that it works for more than just your tests. It allows you to run your fakes in your dev environment as well, providing functionality akin to real environments with the toggles we need to access the real thing when we need to.
Let’s run it through the gauntlet to show how it works and how it solves for all our requirements. First we add the gem to our Gemfile and run bundle install. With the gem installed, we can use the generator rails g webvalve:install to bootstrap a default config file where we can register our fakes.
Then we can generate a fake for our "trading" collaborator service using rails generate webvalve:fake_service Trading. This gives us a class in a conventional location that inherits from WebValve::FakeService. This looks very similar to a Sinatra app, and that's because it is one—with some additional magic baked in.
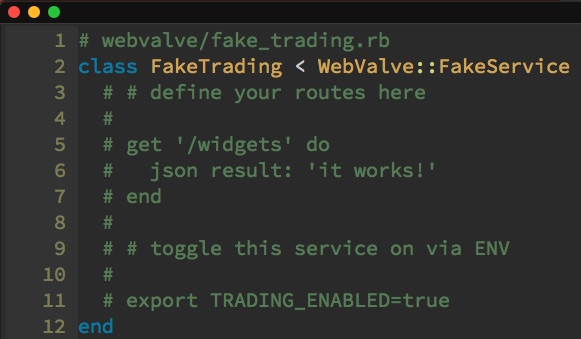

To make this fake work, all we have to do is define the conventionally-named environment variable, TRADINGAPIURL. That tells WebValve what requests to intercept and route to this fake. By inheriting from this WebValve class, we gain the ability to toggle the fake behavior on or off based on another conventionally-named environment variable, in this case TRADING_ENABLED.
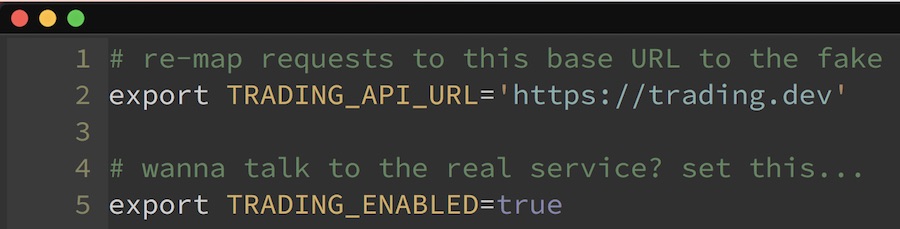
So let’s take our feature spec.
First, we configure out test suite to use WebValve with the RSpec config helper require 'webvalve/rspec'. Then, we look at the user API call—we define a new route for user, in FakeTrading. Then we flesh out that fake route by scooping out our json from the test file and probably making it a little more dynamic when we drop it into the fake. Then we do the same for the deposit API call.
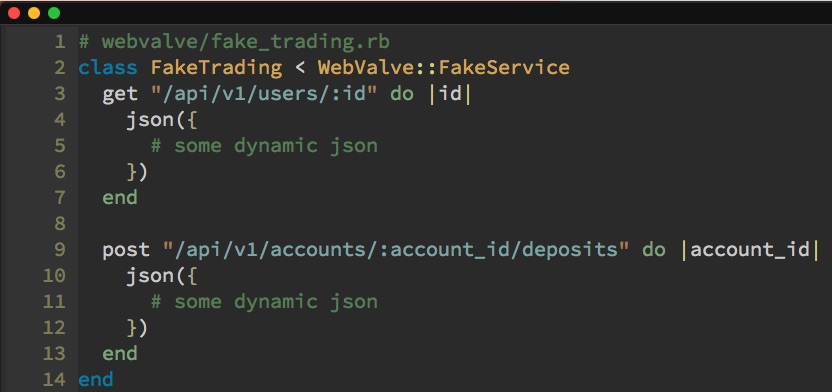
And now our test, which doesn't care about the specifics of either of those API calls, is much clearer. It looks just like our ideal spec from before:
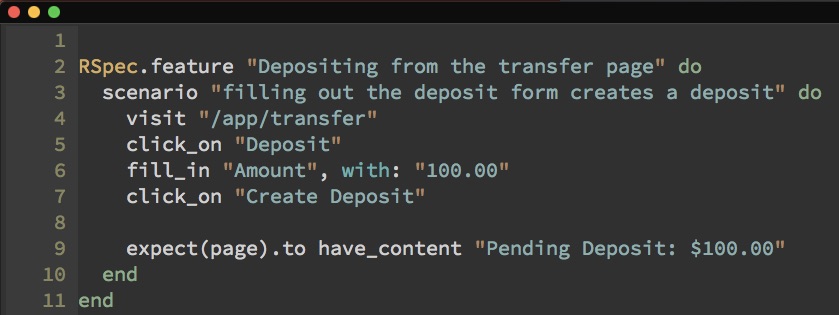
We leverage all the power of WebMock and Sinatra through our conventions and the teeniest configuration to provide all the same functionality as before, but we can write cleaner tests, we get the ability to use these fakes in local development instead of the real services—and we can enable a real service integration without missing a beat.
We’ve achieved our goal—we’ve allowed for all the functionality of integration without the threats of actual integration.
Check it out on GitHub.
This article is part of Engineering at Betterment.