CI/CD: Shortening the Feedback Loop
As we improve and scale our CD platform, shortening the feedback loop with notifications was a small, effective, and important piece.


Continuous Delivery (CD) at scale is hard to get right. At Betterment, we define CD as the process of making every small change to our system shippable as soon as it’s been built and tested. It’s part of the CI/CD (continuous integration and continuous delivery) process. We’ve been doing CD at Betterment for a long time, but it had grown to be quite a cumbersome process over the last few years because our infrastructure and tools hadn’t evolved to meet the needs of our growing engineering team.
We reinvented our Site Reliability Engineering (SRE) team last fall with our sights set on building software to help developers move faster, be happier, and feel empowered. The focus of our work has been on delivering a platform as a service to make sense of the complex process of CD. Coach is the beginning of that platform. Think of something like Heroku, but for engineers here at Betterment. We wanted to build a thoughtfully composed platform based on the tried and true principles of 12-factor apps. In order to build this, we needed to do two overhauls: 1) Build a new CI pipeline and 2) Build a new CD pipeline.
Continuous Integration — Our Principles
For years, we used Jenkins, an open-source tool for automation, and a mess of scripts to provide CI/CD to our engineers. Jenkins is a powerful tool and well-used in the industry, but we decided to cut it because the way that we were using it was wrong, we weren’t pleased with its feature set, and there was too much technical debt to overcome. Tests were flakey and we didn’t know if it was our Jenkins setup, the tests themselves, or both. Dozens of engineers contribute to our biggest repository every day and as the code base and engineering team have grown, the complexity of our CI story has increased and our existing pipeline couldn’t keep up. There were task forces cobbled together to drive up reliability of the test suite, to stamp out flakes, to rewrite, and to refactor. This put a band-aid on the problem for a short while. It wasn’t enough.
We decided to start fresh with CircleCI, an alternative to Jenkins that comes with a lot more opinions, far fewer rough edges, and a lot more stability built-in. We built a tool (Coach) to make the way that we build and test code conventional across all of our of apps, regardless of language, application owner, or business unit. As an added bonus, since our CI process itself was defined in code, if we ever need to switch platforms again, it would be much easier.
Coach was designed and built with these principles:
- Standardize the pipeline — there should be one way to test code, and one way to deploy it
- Test code often — code should be tested as often as it’s committed
- Build artifacts often — code should be built as often as it’s tested so that it can be deployed at any time
- Be environment agnostic — artifacts should be built in an environment-agnostic way with maximum portability
- Give consistent feedback — the CI output should be consistent no matter the language runtime
- Shorten the feedback loop — engineers should receive actionable feedback as soon as possible
Standardizing CI was critical to our growth as an organization for a number of reasons. It ensures that new features can be shipped more quickly, it allows new services to adopt our standardized CI strategy with ease, and it lets us recover faster in the face of disaster — a hurricane causing a power outage at one of our data centers.
Our goal was to replace the old way of building and testing our applications (what we called the “Old World”) and start fresh with these principles in mind (what we deemed the “New World”). Using our new platform to build and test code would allow our engineers to receive automated feedback sooner so they could iterate faster. One of our primary aims in building this platform was to increase developer velocity, so we needed to eliminate any friction from commit to deploy. Friction here refers to ambiguity of CI results and the uncertainty of knowing where your code is in the CI/CD process. Shortening the feedback loop was one of the first steps we took in building out our new platform, and we’re excited to share the story of how we designed that solution.
Our Principles in Action: Shortening the Feedback Loop
The feedback loop in the Old World run by Jenkins was one of the biggest hurdles to overcome. Engineers never really knew where their code was in the pipeline. We use Slack, like a lot of other companies, so that part of the messaging story wouldn’t change, but there were bugs we needed to fix and design flaws we needed to update. How much feedback should we give? When do we want to give feedback? How detailed should our messages be? These were some of the questions we asked ourselves during this part of the design phase.
What our Engineers Needed
For pull requests, developers would commit code and push it up to GitHub and then eventually they would receive a Slack message that said “BAD” for every test suite that failed, or “GOOD” if everything passed, or nothing at all in the case of a Jenkins agent getting stuck and hanging forever. The notifications were slightly more nuanced than good/bad, but you get the idea. We valued sending Slack messages to our engineers, as that’s how the company communicates most effectively, but we didn’t like the rate of communication or the content of those messages. We knew both of those would need to change.
As for merges into master, the way we sent Slack messages to communicate to engineering teams (as opposed to just individuals) was limited because of how our CI/CD process was constructed. The entire CI and CD process happened as a series of interwoven Jenkins freestyle jobs. We never got the logic quite right around determining whose code was being deployed — the deploy logic was contingent on a pretty rough shell script called “inside a Jenkins job.” The best we had was a Slack message that was sent roughly five minutes before a deploy began, tagging a good estimation of contributors but often missing someone if their Github email address was different from their Slack email address. More critically, the one-off script solution wasn’t stored in source control, therefore it wasn’t tested. We had no idea when it failed or missed tagging some contributors. We liked notifying engineers when a deploy began, but we needed to be more accurate about who we were notifying.
What our SRE Team Needed
Our design and UX was informed by what our engineers using our platform needed, but Coach was built based on our needs. What did we need? Well-tested code stored in version control that could easily be changed and developed. All of the code that handles changesets and messaging logic in the New World is written in one central location, and it’s tested in isolation. Our CI/CD process invokes this code when it needs to, and it works great. We can be confident that the right people are notified at the right time because we wrote code that does that and we tested it. It’s no longer just a script that sometimes works and sometimes doesn’t. Because it’s in source control and it runs through its own CI process, we can also easily roll out changes to notifications without breaking things.
We wanted to build our platform around what our engineers would need to know, when they need to know it, and how often. And so one of the first components we built out was this new communication pipeline. Next we’ll explore in more detail some of our design choices regarding the content of our messages and the rate at which we send them.
Make sure our engineers don’t mute their slack notifications
In leaving the Old World of inconsistent and contextually sparse communication we looked at our blank canvas and initially thought “every time the tests pass, send a notification! That will reduce friction!” So we tried that. If we merged code into a tracked branch — a branch that multiple engineers contribute to, like master — for one of our biggest repos, which contained 20 apps and 20 test suites, we would be notified at every transition: every rubocop failure, every flakey occurrence of a feature test. We quickly realized it was too much.
We sat back and thought really hard about what we would want, considering we were dogfooding our own pipeline. How often did we want to be notified by the notification system when our tests that tested the code that built the notification system, succeeded? Sheesh, that’s a mouthful. Our Slack bot could barely keep up!
We decided it was necessary to be told only once when everything ran successfully. However, for failures, we didn’t want to sit around for five minutes crossing our fingers hoping that everything was successful only to be told that we could have known three minutes earlier that we’d forgotten a newline at the end of one of our files. Additionally, in CircleCI where we can easily parallelize our test suites, we realized we wouldn’t want to notify someone for every chunk of the test suite that failed, just the first time a failure happened for the suite.
We came up with a few rules to design this part of the system:
- Let the author know as soon as possible when something is red but don’t overdo it for redundant failures within the same job (e.g. if unit tests ran on 20 containers and 18 of them saw failures, only notify once)
- Only notify once about all the green things
- Give as much context as possible without being overwhelming: be concise but clear
Next we’ll explore the changes we made in content.
What to say when things fail
This is what engineers would see in the Old World when tests failed for an open pull request:

Among other deficiencies, there’s only one link and it takes us to a Jenkins job. There’s no context to orient us quickly to what the notification is for.
After considering what we were currently sending our engineers, we realized that 1) context and 2) status were the most important things to communicate, which were the aspects of our old messaging that were suffering the most.
Here’s what we came up with:

Thanks Coach bot! Right away we know what’s happened. A PR build failed. It failed for a specific GitHub branch (“what-to-say-when-things-fail-branch”), in a specific repo (“Betterment/coach”), for a specific PR (#430),for a specific job in the test suite (“coach_cli — lint (Gemfile)”). We can click on any of these links and know exactly where they go based on the logo of the service. Messages about failures are now actionable and full of context,prompting the engineer to participate in CI, to go directly to their failures or to their PR. And this bounty of information helps a lot if the engineer has multiple PRs open and needs to quickly switch context.
The messaging that happened for failures when you merged a pull request into master was a little different in that it included mentions for the relevant contributors (maybe all of them, if we were lucky!):
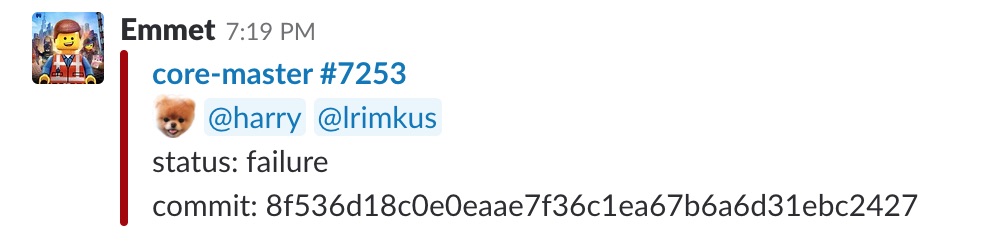
The New World is cleaner, easier to grok, and more immediately helpful:
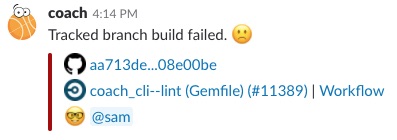
The link title to GitHub is the commit diff itself, and it takes you to the compare URL for that changeset. The CircleCI info includes the title of the job that failed (“coach_cli — lint (Gemfile)”), the build number (“#11389”) to reference for context in case there are multiple occurrences of the failure in multiple workflows, a link to the top-level “Workflow”, and @s for each contributor.
What to say when things succeed
We didn’t change the frequency of messaging for success — we got that right the first time around. You got one notification message when everything succeeded and you still do. But in the Old World there wasn’t enough context to make the message immediately useful. Another disappointment we had with the old messaging was that it didn’t make us feel very good when our tests passed. It was just a moment in time that came and went:

In the New World we wanted to proclaim loudly (or as loudly as you can proclaim in a Slack message) that the pull request was successful in CI:
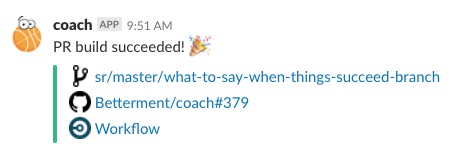
Tada! We did it! We wanted to maintain the same format as the new failure messages for consistency and ease of reading. The links to the various services we use are in the same order as our new failure messages, but the link to CircleCI only goes to the workflow that shows the graph of all the tests and jobs that ran. It’s delightful and easy to parse and has just the right amount of information.
What’s next?
We have big dreams for the future of this platform with more and more engineers using our product. Shortening the feedback loop with notifications is only one small, but rather important, part of our CD platform. In the next post of this series on CD, we’ll explore how we committed 5000 line configuration files to our repositories with confidence by standardizing CI for different runtimes, automating config generation in code, and testing that code generation.
We believe in a world where shipping code, even in really large codebases with lots of contributors, should be done dozens of times a day. Where engineers can experience feedback about their code with delight and simplicity. We’re building that at Betterment.