From 1 to N: Distributed Data Processing with Airflow
Betterment has built a highly available data processing platform to power new product features and backend processing needs using Airflow.


Betterment’s data platform is unique in that it not only supports offline needs such as analytics, but also powers our consumer-facing product. Features such as Time Weighted Returns and Betterment for Business balances rely on our data platform working throughout the day. Additionally, we have regulatory obligations to report complex data to third parties daily, making data engineering a mission critical part of what we do at Betterment.
We originally ran our data platform on a single machine in 2015 when we ingested far less data with fewer consumer-facing requirements. However, recent customer and data growth coupled with new business requirements require us to now scale horizontally with high availability.
Transitioning from Luigi to Airflow
Our single-server approach used Luigi, a Python module created to orchestrate long-running batch jobs with dependencies. While we could achieve high availability with Luigi, it’s now 2017 and the data engineering landscape has shifted. We turned to Airflow because it has emerged as a full-featured workflow management framework better suited to orchestrate frequent tasks throughout the day.
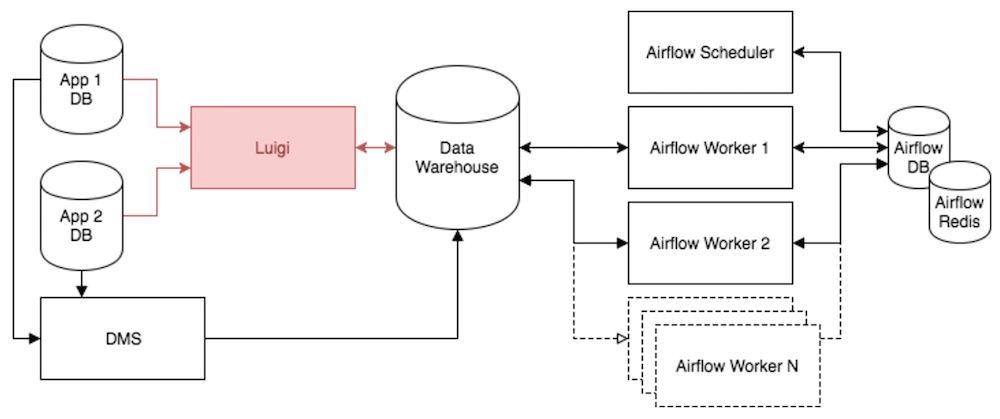
To migrate to Airflow, we’re deprecating our Luigi solution on two fronts: cross-database replication and task orchestration. We’re using Amazon’s Database Migration Service (DMS) to replace our Luigi-implemented replication solution and re-building all other Luigi workflows in Airflow. We’ll dive into each of these pieces below to explain how Airflow mediated this transition.
Cross-Database Replication with DMS
We used Luigi to extract and load source data from multiple internal databases into our Redshift data warehouse on an ongoing basis. We recently adopted Amazon’s DMS for continuous cross-database replication to Redshift, moving away from our internally-built solution.
The only downside of DMS is that we are not aware of how recent source data is in Redshift. For example, a task computing all of a prior day’s activity executed at midnight would be inaccurate if Redshift were missing data from DMS at midnight due to lag.
In Luigi, we knew when the data was pulled and only then would we trigger a task. However, in Airflow we reversed our thinking to embrace DMS, using Airflow’s sensor operators to wait for rows to be pushed from DMS before carrying on with dependent tasks.
High Availability in Airflow
While Airflow doesn’t claim to be highly available out of the box, we built an infrastructure to get as close as possible. We’re running Airflow’s database on Amazon’s Relational Database Service and using Amazon’s Elasticache for Redis queuing. Both of these solutions come with high availability and automatic failover as add-ons Amazon provides. Additionally, we always deploy multiple baseline Airflow workers in case one fails, in which case we use automated deploys to stand up any part of the Airflow cluster on new hardware.
There is still one single point of failure left in our Airflow architecture though: the scheduler. While we may implement a hot-standby backup in the future, we simply accept it as a known risk and set our monitoring system to notify a team member of any deviances.
Cost-Effective Scalability
Since our processing needs fluctuate throughout the day, we were paying for computing power we didn’t actually need during non-peak times on a single machine, as shown in our Luigi server’s load. 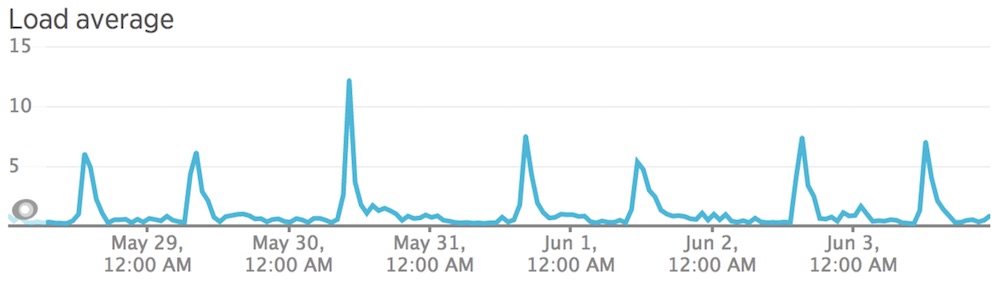
Distributed workers used with Amazon’s Auto Scaling Groups allow us to automatically add and remove workers based on outstanding tasks in our queues. Effectively, this means maintaining only a baseline level of workers throughout the day and scaling up during peaks when our workload increases.
Airflow queues allow us to designate certain tasks to run on particular hardware (e.g. CPU optimized) to further reduce costs. We found just a few hardware type queues to be effective. For instance, tasks that saturate CPU are best run on a compute optimized worker with concurrency set to the number of cores. Non-CPU intensive tasks (e.g. polling a database) can run on higher concurrency per CPU core to save overall resources.
Extending Airflow Code
Airflow tasks that pass data to each other can run on different machines, presenting a new challenge versus running everything on a single machine. For example, one Airflow task may write a file and a subsequent task may need to email the file from the dependent task ran on another machine. To implement this pattern, we use Amazon S3 as a persistent storage tier. 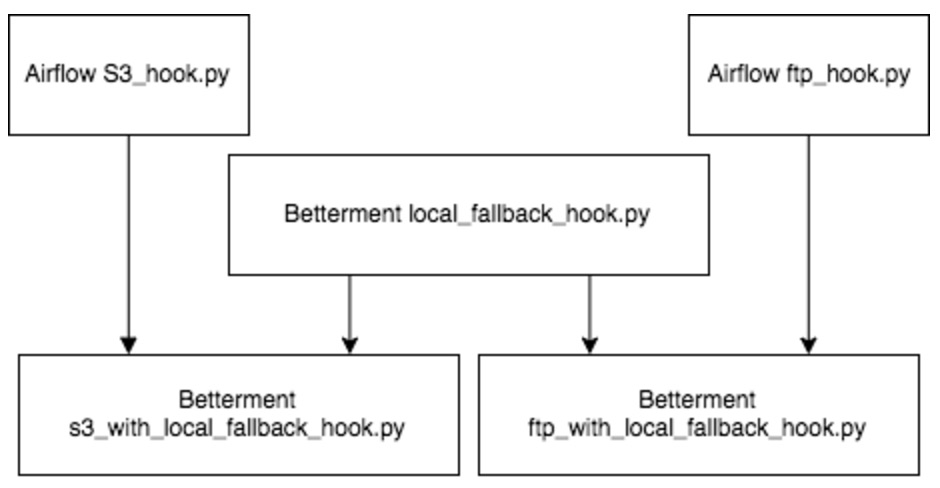
Fortunately, Airflow already maintains a wide selection of hooks to work with remote sources such as S3. While S3 is great for production, it’s a little difficult to work with in development and testing where we prefer to use the local filesystem. We implemented a “local fallback” mixin for Airflow maintained hooks that uses the local filesystem for development and testing, deferring to the actual hook’s remote functionality only on production.
Development & Deployment
We mimic our production cluster as closely as possible for development & testing to identify any issues that may arise with multiple workers. This is why we adopted Docker to run a production-like Airflow cluster from the ground up on our development machines. We use containers to simulate multiple physical worker machines that connect to officially maintained local Redis and PostgreSQL containers.
Development and testing also require us to stand up the Airflow database with predefined objects such as connections and pools for the code under test to function properly. To solve this programmatically, we adopted Alembicdatabase migrations to manage these objects through code, allowing us to keep our development, testing, and production Airflow databases consistent.
Graceful Worker Shutdown
Upon each deploy, we use Ansible to launch new worker instances and terminate existing workers. But what happens when our workers are busy with other work during a deploy? We don’t want to terminate workers while they’re finishing something up and instead want them to terminate after the work is done (not accepting new work in the interim).
Fortunately, Celery supports this shutdown behavior and will stop accepting new work after receiving an initial TERM signal, letting old work finish up. We use Upstart to define all Airflow services and simply wrap the TERM behavior in our worker’s post-stop script, sending the TERM signal first, waiting until we see the Celery process stopped, then finally poweroff the machine.
Conclusion
The path to building a highly available data processing service was not straightforward, requiring us to build a few specific but critical additions to Airflow. Investing the time to run Airflow as a cluster versus a single machine allows us to run work in a more elastic manner, saving costs and using optimized hardware for particular jobs. Implementing a local fallback for remote hooks made our code much more testable and easier to work with locally, while still allowing us to run with Airflow-maintained functionality in production.
While migrating from Luigi to Airflow is not yet complete, Airflow has already offered us a solid foundation. We look forward to continuing to build upon Airflow and contributing back to the community.
This article is part of Engineering at Betterment.