Why (And How) Betterment Is Using Julia
Betterment is using Julia to solve our own version of the “two-language problem."

Betterment is using Julia to solve our own version of the “two-language problem."
At Betterment, we’re using Julia to power the projections and recommendations we provide to help our customers achieve their financial goals. We’ve found it to be a great solution to our own version of the “two-language problem”–the idea that the language in which it is most convenient to write a program is not necessarily the language in which it makes the most sense to run that program. We’re excited to share the approach we took to incorporating it into our stack and the challenges we encountered along the way.
Working behind the scenes, the members of our Quantitative Investing team bring our customers the projections and recommendations they rely on for keeping their goals on-track. These hard-working and talented individuals spend a large portion of their time developing models, researching new investment ideas and maintaining our research libraries. While they’re not engineers, their jobs definitely involve a good amount of coding. Historically, the team has written code mostly in a research environment, implementing proof-of-concept models that are later translated into production code with help from the engineering team.
Recently, however, we’ve invested significant resources in modernizing this research pipeline by converting our codebase from R to Julia and we’re now able to ship updates to our quantitative models quicker, and with less risk of errors being introduced in translation. Currently, Julia powers all the projections shown inside our app, as well as a lot of the advice we provide to our customers. The Julia library we built for this purpose serves around 18 million requests per day, and very efficiently at that.
Examples of projections and recommendations at Betterment. Does not reflect any actual portfolio and is not a guarantee of performance.
Why Julia?
At QCon London 2019, Steve Klabnik gave a great talk on how the developers of the Rust programming language view tradeoffs in programming language design. The whole talk is worth a watch, but one idea that really resonated with us is that programming language design—and programming language choice—is a reflection of what the end-users of that language value and not a reflection of the objective superiority of one language over another. Julia is a newer language that looked like a perfect fit for the investing team for a number of reasons:
- Speed. If you’ve heard one thing about Julia, it’s probably about it’s blazingly fast performance. For us, speed is important as we need to be able to provide real-time advice to our customers by incorporating their most up-to-date financial scenario in our projections and recommendations. It is also important in our research code where the iterative nature of research means we often have to re-run financial simulations or models multiple times with slight tweaks.
- Dynamicism. While speed of execution is important, we also require a dynamic language that allows us to test out new ideas and prototype rapidly. Julia ticks the box for this requirement as well by using a just-in-time compiler that accommodates both interactive and non-interactive workflows well. Julia also has a very rich type system where researchers can build prototypes without type declarations, and then later refactoring the code where needed with type declarations for dispatch or clarity. In either case, Julia is usually able to generate performant compiled code that we can run in production.
- Relevant ecosystem. While the nascency of Julia as a language means that the community and ecosystem is much smaller than those of other languages, we found that the code and community oversamples on the type of libraries that we care about. Julia has excellent support for technical computing and mathematical modelling.
Given these reasons, Julia is the perfect language to serve as a solution to the “two-language problem”. This concept is oft-quoted in Julian circles and is perfectly exemplified by the previous workflow of our team: Investing Subject Matter Experts (SMEs) write domain-specific code that’s solely meant to serve as research code, and that code then has to be translated into some more performant language for use in production. Julia solves this issue by making it very simple to take a piece of research code and refactor it for production use.
Our approach
We decided to build our Julia codebase inside a monorepo, with separate packages for each conceptual project we might work on, such as interest rate models, projections, social security amount calculations and so on. This works well from a development perspective, but we soon faced the question of how best to integrate this code with our production code, which is mostly developed in Ruby. We identified two viable alternatives:
- Build a thin web service that will accept HTTP requests, call the underlying Julia functions, and then return a HTTP response.
- Compile the Julia code into a shared library, and call it directly from Ruby using FFI.
Option 1 is a very common pattern, and actually quite similar to what had been the status quo at Betterment, as most of the projections and recommendation code existed in a JavaScript service.
It may be surprising then to learn that we actually went with Option 2. We were deeply attracted to the idea of being able to fully integration-test our projections and recommendations working within our actual app (i.e. without the complication of a service boundary). Additionally, we wanted an integration that we could spin-up quickly and with low ongoing cost; there’s some fixed cost to getting a FFI-embed working right—but once you do, it’s an exceedingly low cost integration to maintain. Fully-fledged services require infrastructure to run and are (ideally) supported by a full team of engineers.
That said, we recognize the attractive properties of the more well-trodden Option 1 path and believe it could be the right solution in a lot of scenarios (and may become the right solution for us as our usage of Julia continues to evolve).
Implementation
Given how new Julia is, there was minimal literature on true interoperability with other programming languages (particularly high-level languages–Ruby, Python, etc). But we saw that the right building blocks existed to do what we wanted and proceeded with the confidence that it was theoretically possible.
As mentioned earlier, Julia is a just-in-time compiled language, but it’s possible to compile Julia code ahead-of-time using PackageCompiler.jl. We built an additional package into our monorepo whose sole purpose was to expose an API for our Ruby application, as well as compile that exposed code into a C shared library. The code in this package is the glue between our pure Julia functions and the lower level library interface—it’s responsible for defining the functions that will be exported by the shared library and doing any necessary conversions on input/output.
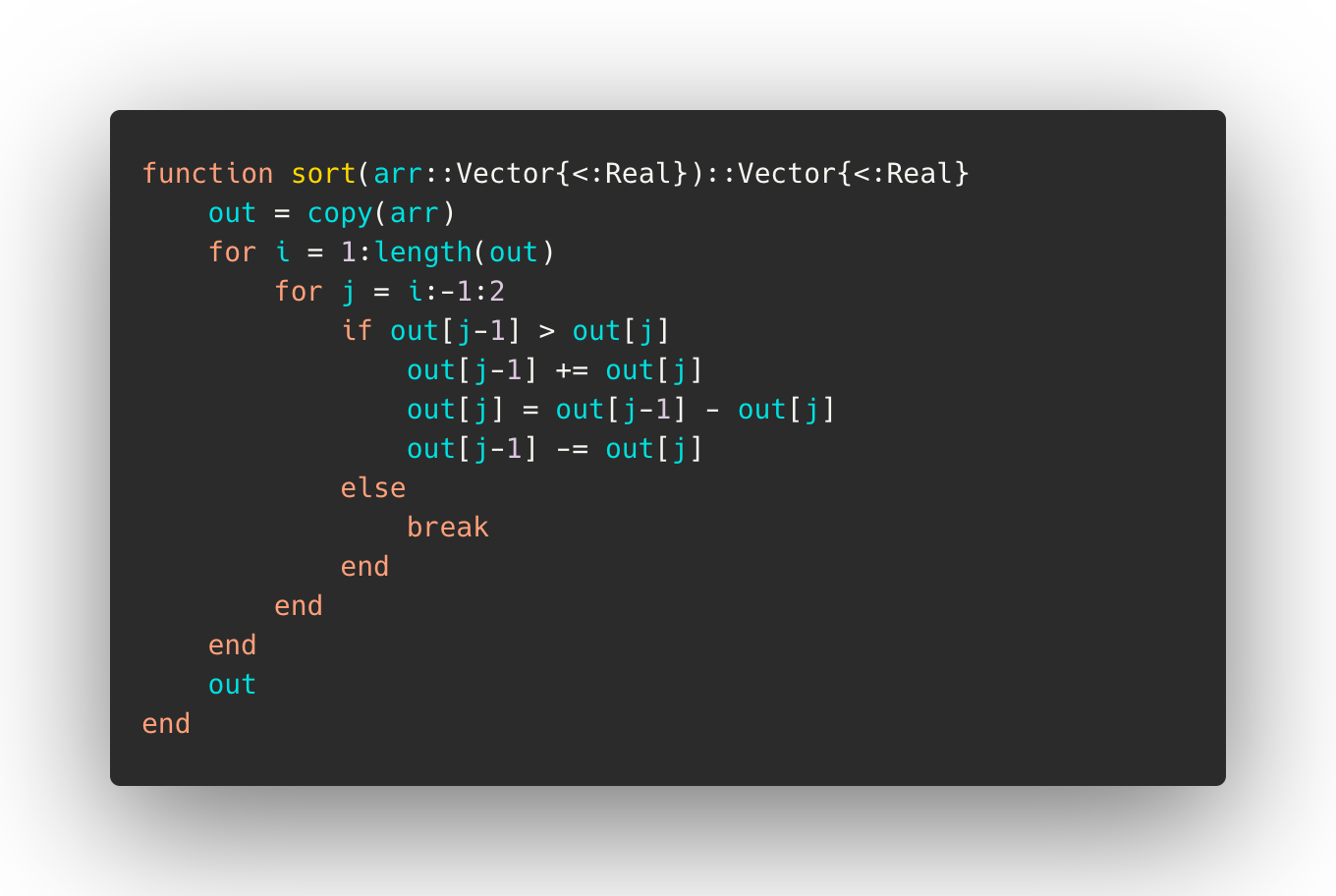
As an example, consider the following simple Julia function which sorts an array of numbers using the insertion sort algorithm:
In order to be able to expose this in a shared library, we would wrap it like this:
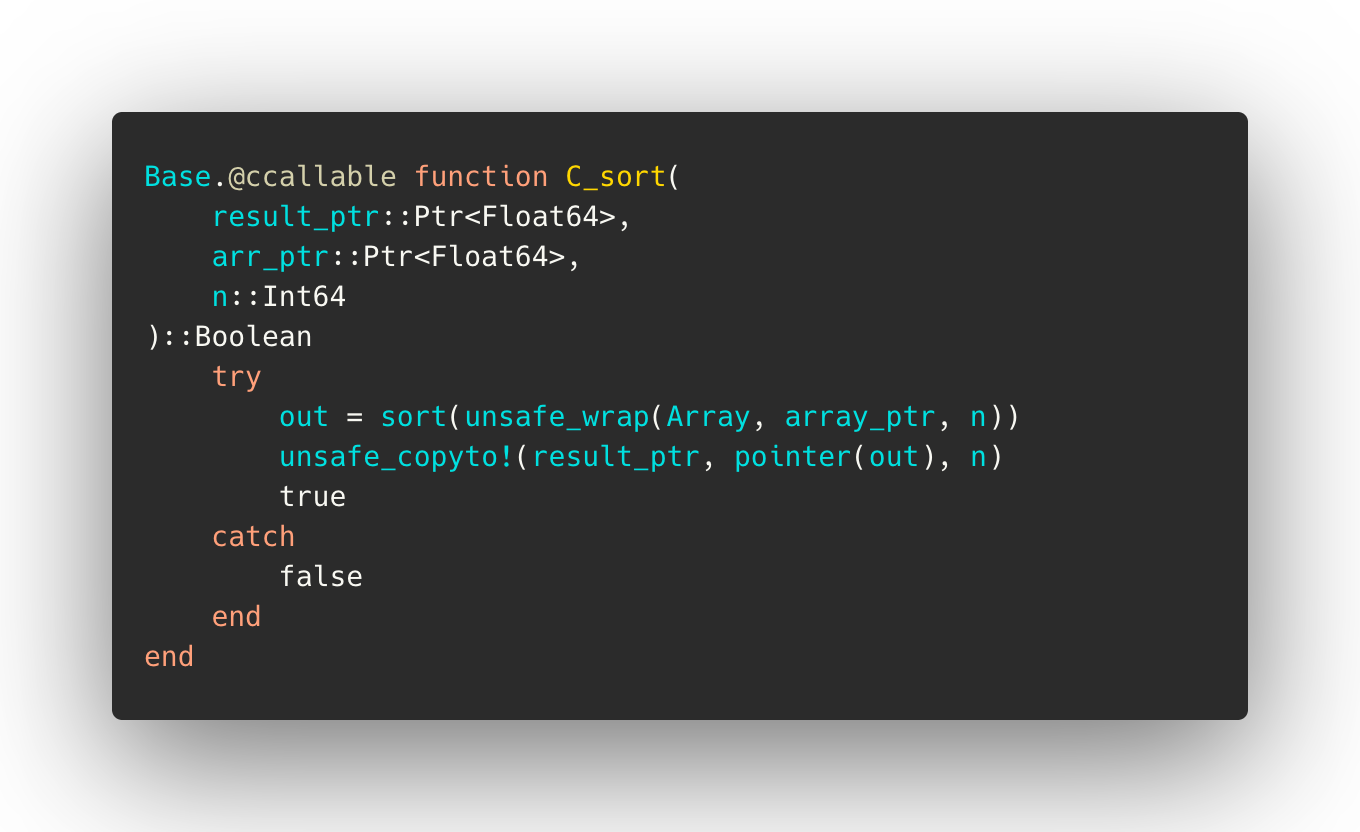
Here we’ve simplified memory management by requiring the caller to allocate memory for the result, and implemented primitive exception handling (see Challenges & Pitfalls below).
On the Ruby end, we built a gem which wraps our Julia library and attaches to it using Ruby-FFI. The gem includes a tiny Julia project with the API library as it’s only dependency. Upon gem installation, we fetch the Julia source and compile it as a native extension.
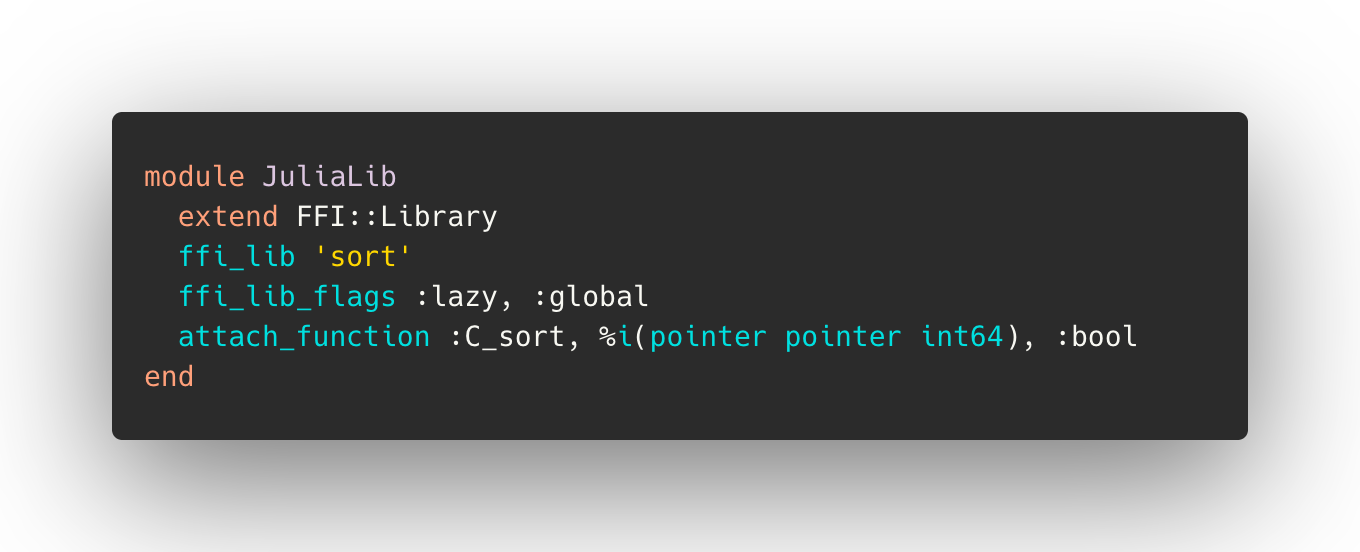
Attaching to our example function with Ruby-FFI is straightforward:
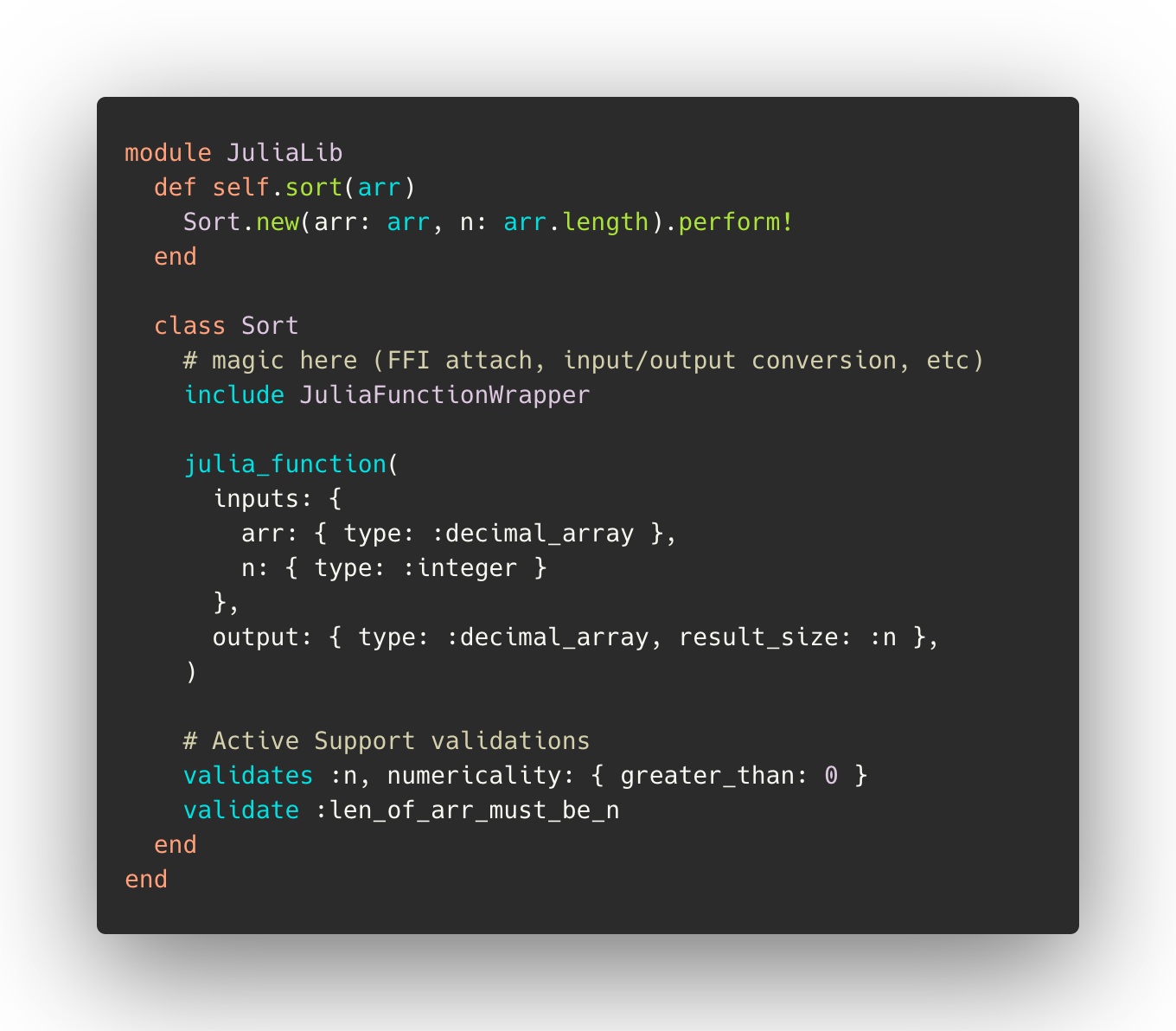
From here, we could begin using our function, but it wouldn’t be entirely pleasant to work with–converting an input array to a pointer and processing the result would require some tedious boilerplate. Luckily, we can use Ruby’s powerful metaprogramming abilities to abstract all that away–creating a declarative way to wrap an arbitrary Julia function which results in a familiar and easy-to-use interface for Ruby developers. In practice, that might look something like this:
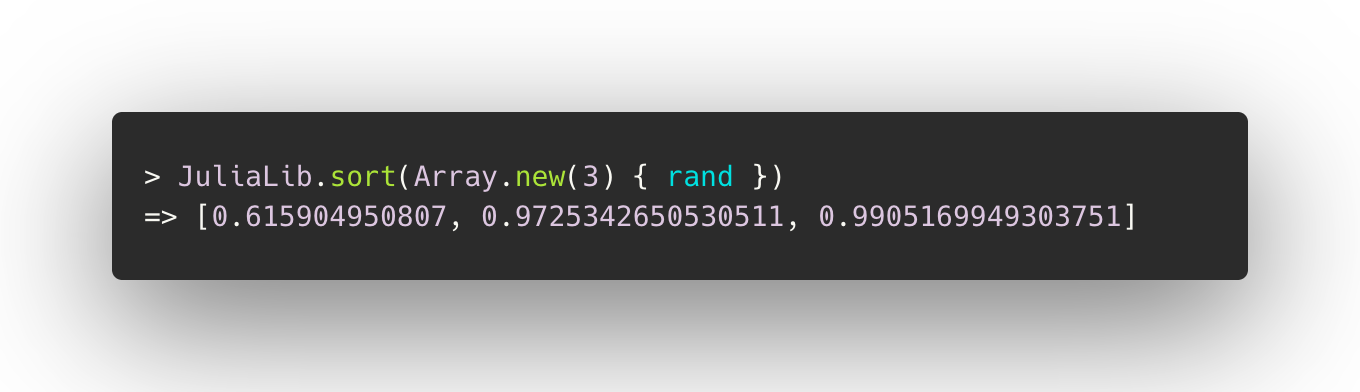
Resulting in a function for which the fact that the underlying implementation is in Julia has been completely abstracted away:
Challenges & Pitfalls
Debugging an FFI integration can be challenging; any misconfiguration is likely to result in the dreaded segmentation fault–the cause of which can be difficult to hunt down. Here are a few notes for practitioners about some nuanced issues we ran into, that will hopefully save you some headaches down the line:
- The Julia runtime has to be initialized before calling the shared library. When loading the dynamic library (whether through Ruby-FFI or some other invocation of `dlopen`), make sure to pass the flags `RTLD_LAZY` and `RTLD_GLOBAL` (`ffi_lib_flags :lazy, :global` in Ruby-FFI).
- If embedding your Julia library into a multi-threaded application, you’ll need additional tooling to only initialize and make calls into the Julia library from a single thread, as multiple calls to `jl_init` will error. We use a multi-threaded web server for our production application, and so when we make a call into the Julia shared library, we push that call onto a queue where it gets picked up and performed by a single executor thread which then communicates the result back to the calling thread using a promise object.
- Memory management–if you’ll be passing anything other than primitive types back from Julia to Ruby (e.g. pointers to more complex objects), you’ll need to take care to ensure the memory containing the data you’re passing back isn’t cleared by the Julia garbage collector prior to being read on the Ruby side. Different approaches are possible. Perhaps the simplest is to have the Ruby side allocate the memory into which the Julia function should write it’s result (and pass the Julia function a pointer to that memory). Alternatively, if you want to actually pass complex objects out, you’ll have to ensure Julia holds a reference to the objects beyond the life of the function, in order to keep them from being garbage collected. And then you’ll probably want to expose a way for Ruby to instruct Julia to clean up that reference (i.e. free the memory) when it’s done with it (Ruby-FFI has good support for triggering a callback when an object goes out-of-scope on the Ruby side).
- Exception handling–conveying unhandled exceptions across the FFI boundary is generally not possible. This means any unhandled exception occurring in your Julia code will result in a segmentation fault. To avoid this, you’ll probably want to implement catch-all exception handling in your shared library exposed functions that will catch any exceptions that occur and return some context about the error to the caller (minimally, a boolean indicator of success/failure).
Tooling
To simplify development, we use a lot of tooling and infrastructure developed both in-house and by the Julia community.
Since one of the draws of using Julia in the first place is the performance of the code, we make sure to benchmark our code during every pull request for potential performance regressions using the BenchmarkTools.jl package.
To facilitate versioning and sharing of our Julia packages internally (e.g. to share a version of the Ruby-API package with the Ruby gem which wraps it) we also maintain a private package registry. The registry is a separate Github repository, and we use tooling from the Registrator.jl package to register new versions. To process registration events, we maintain a registry server on an EC2 instance provisioned through Terraform, so updates to the configuration are as easy as running a single `terraform apply` command.
Once a new registration event is received, the registry server opens a pull request to the Julia registry. There, we have built in automated testing that resolves the version of the package that is being tested, looks up any reverse dependencies of that package, resolves the compatibility bounds of those packages to see if the newly registered version could lead to a breaking change, and if so, runs the full test suites of the reverse dependencies. By doing this, we can ensure that when we release a patch or minor version of one of our packages, we can ensure that it won’t break any packages that depend on it at registration time. If it would, the user is instead forced to either fix the changes that lead to a downstream breakage, or to modify the registration to be a major version increase.
Takeaways
Though our venture into the Julia world is still relatively young compared to most of the other code at Betterment, we have found Julia to be a perfect fit in solving our two-language problem within the Investing team. Getting the infrastructure into a production-ready format took a bit of tweaking, but we are now starting to realize a lot of the benefits we hoped for when setting out on this journey, including faster development of production ready models, and a clear separation of responsibilities between the SMEs on the Investing team who are best suited for designing and specifying the models, and the engineering team who have the knowledge on how to scale that code into a production-grade library. The switch to Julia has allowed us not only to optimize and speed up our code by multiple orders of magnitude, but also has given us the environment and ecosystem to explore ideas that would simply not be possible in our previous implementations.